






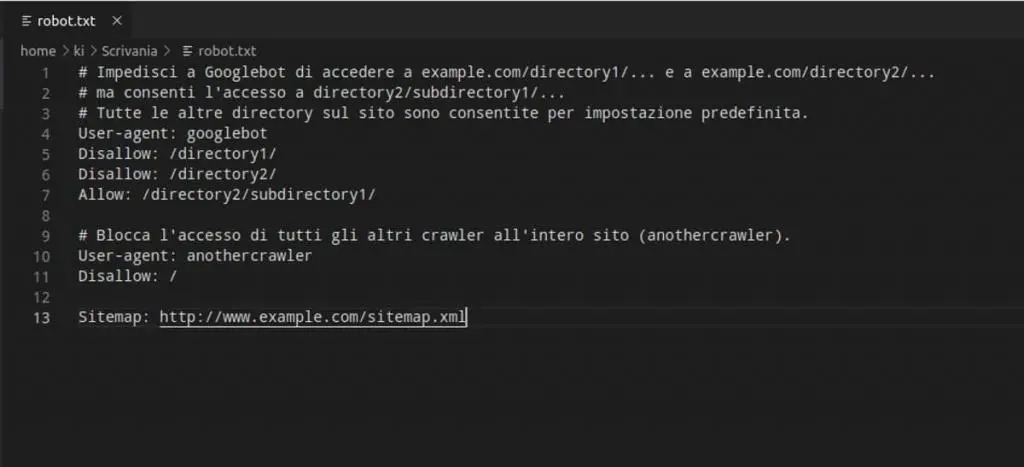

Il file robots.txt è un file di testo, codificato in ASCII o UTF-8 e localizzato nella directory principale di un sito. Viene utilizzato per dare indicazioni ai crawler dei motori di ricerca su quali pagine o file possono evitare di scansionare all’interno del sito. Serve principalmente per evitare un sovraccarico di richieste al sito.
Da fine luglio, chi usa Google Search Console è stato preallertato circa la scadenza del 1° settembre. Da questa data cambiano le regole per l’indicizzazione delle pagine: Google non seguirà più noindex, nofollow e crawl-delay in robots.txt. In particolare cambia la gestione dei noindex nei file robots.txt.
Come fare d’ora in poi per bloccare l’indicizzazione di una pagina? In attesa che si arrivi alla definitiva standardizzazione dei file robots.txt, ecco i metodi per continuare a bloccare l’indicizzazione di una pagina:
- utilizzare noindex nei meta tag robots direttamente nel codice HTML della pagina: è il metodo migliore per rimuovere le URL dall’indice;
- usare i codici di stato 404 e 401: entrambi i i codici indicano una pagina non esistente, che quindi verrà scartata da Google subito dopo il crawl;
- proteggere le pagine con una password per l’accesso: generalmente le pagine con accesso protetto da password non vengono mostrate nei risultati di ricerca;
- usare i disallow nei file robots.txt;
- usare lo strumento di rimozione degli URL all’interno della Google Search Console: è un’alternativa rapida e semplice per la momentanea rimozione delle URL.